Mapping Your Dark Matter
Posted by: Matt SalerI’m the kind of person who will immediately pick up any book of Hubble Space Telescope photos or read about galaxies in my spare time. I make Phil Plait’s Bad Astronomy blog a daily must-read and have a sky map app on my phone’s homescreen. I’ve currently got two different space photos set as my desktop background on two monitors.
I don’t claim any real level of expertise, but I’m fascinated by this stuff.
I mean, look at this mosaic of the Andromeda Galaxy:

If you look at a hi-res version, it looks pixelated, but it’s not. Those are stars. Mind-blowing, huh?
This post isn’t just an excuse to post some great space photos, though it’s at least partly that. Here’s another:

That’s our galactic center, including the region containing a supermassive black hole in the white area on the right.
But that’s just the stuff we can see.
Dark Matter
My amateur interest in space recently got me thinking about how something we can’t see, a concept in astrophysics called dark matter, might relate to my professional interest in content and the work we do with it for our clients.
I’ll let Neil DeGrasse Tyson explain what dark matter is:
The too-long-didn’t-watch version: it’s something we know must exist, but don’t know much of anything about. Yet.
Phil Plait goes into slightly more detail:
Dark matter was discovered a long time ago, when it was found that galaxies that live in clusters were moving way too fast to be held by the cluster gravity. They should just simply shoot away, and clusters would essentially evaporate. This implied that clusters of galaxies were either very young and hadn’t had time to dissolve — which we knew wasn’t true; they’re clearly old — or there must be a lot more gravity holding them together. We can add up all the light from the stars in the galaxies and estimate their total mass, but what you get is only about 5-10% of the mass needed to hold clusters together. So most of the matter making up the clusters must be dark. Otherwise we’d see it.
It’s also what gives galaxies their rotation speed—without it, galaxies would rotate slower.
Dark matter is an essential piece of the cosmos. The problem is that we can’t observe it directly, which makes learning more about it difficult. But we’re working on that.
Cosmologist Sean Carroll recently explained why it’s important to study dark matter, despite the fact that we can’t see it:
Only 5 percent of the universe, by mass, is the ordinary stuff out of which you and I are made. So, if you care about understanding the universe, 95 percent of it is dark matter and dark energy. If you want to know how the universe works, you have to understand that stuff. (my emphasis)
Carroll went on to say,
It’s very annoying to us, as scientists, because we know it’s there. We know how much of it is there. We know where it is. But we don’t know what it is. We don’t know what is actually making up the dark matter. So the more we can study its properties, how it collects, how it evolves over time, the more of a hope we get to understand what it is made out of and why there is dark matter at all.
Those comments from Carroll come from a news piece about a dark matter map scientists with the Dark Matter Survey released earlier this year (below).
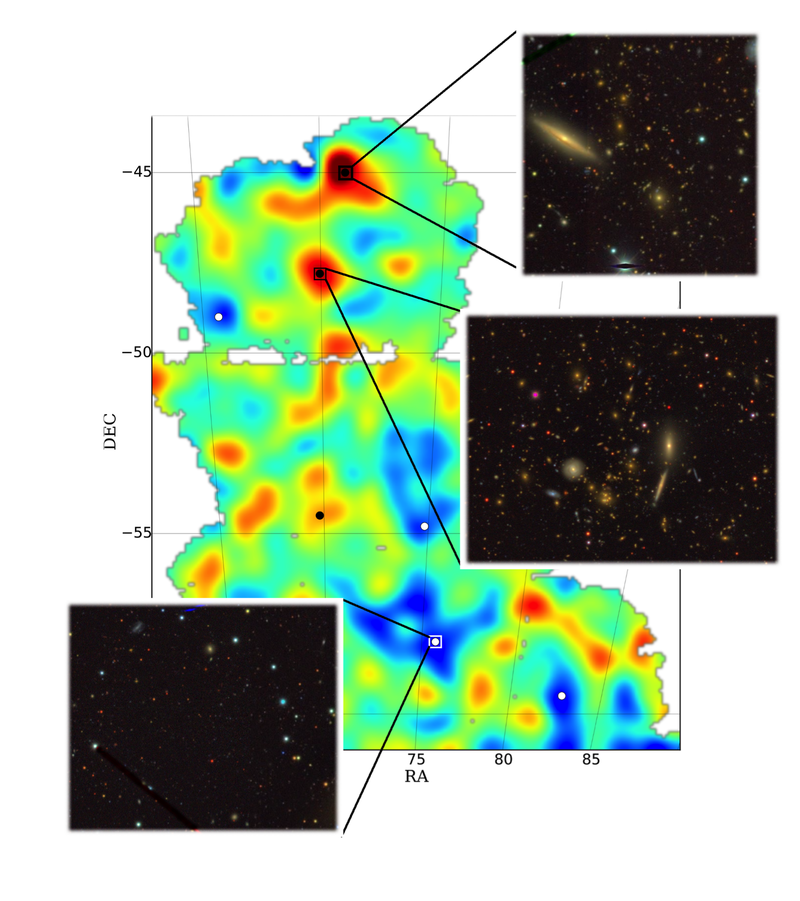 The team of scientists used computers to painstakingly study 2 million galaxies in a miniscule patch of sky, detecting tiny changes in apparent shape in those galaxies caused by dark matter’s gravity distorting their light.
The team of scientists used computers to painstakingly study 2 million galaxies in a miniscule patch of sky, detecting tiny changes in apparent shape in those galaxies caused by dark matter’s gravity distorting their light.
The reason for making this map is that quest for knowledge about the universe Carroll talks about above. Maps like this help scientists make sense of what we see out there, whether it’s how galaxies form, move and evolve, or how they collect together in clumps. Maps like this helps scientists take dark matter into account.
What does this have to do with content?
At the start of many web projects, content is like dark matter. It’s something—text, data, graphics, video, audio—both agency and client know exists, but it’s not fully understood. We know it’s essential to the website, that it makes up the largest chunk of the site’s mass, that without it the site wouldn’t work or hold together very well.
Despite that, it’s easy to get caught up in what I’ll call the luminous material, the design and development. Those are the stars and galaxies of the web, the stuff that’s easy to see and conceptualize—and they’re essential pieces.
However, design and development without a full accounting of content is like cosmology in the days before the discovery of dark matter. At the time, scientists’ theories for galaxy rotation and clustering didn’t match up with observation. Model galaxies would fall apart, because dark matter wasn’t part of the equation. The models had to adapt for the presence of the stuff in order to work.
The same is true for websites: you need to understand your content if you want to keep your site from falling apart or spinning too slowly.
Fortunately, we can observe content directly. If we take the time, we can catalog it, organize it, adjust it, cull it, create it, plan for its future, and more. In other words, we can build a dark matter map. We call this map content strategy.
Content strategy is an essential component to any successful website project. A good content strategy will tell you what you have, why you have it, what you need, and where you’re going with it. It will align with and inform your goals, making them achievable from where you are now. It will turn your dark matter into a fully-known piece of the puzzle.
We’re interested in helping you discover what makes up your dark matter. Together, we’ll plot out how it collects and evolves. And we’ll help you plan for its future.
What can we map for you?
Owner Summit 2015
Posted by: Brion Eriksen
On January 8-9, 2015 I had the pleasure of attending Owner Summit in Austin, Texas. Owner Summit is a two-day event delivered by Bureau of Digital, an organization created by Greg Hoy and Greg Storey of Happy Cog and partner Carl Smith. Happy Cog is an industry-leading digital agency that also produces the longtime industry-benchmark web site A List Apart (as well as the publication series A Book Apart). With that impressive pedigree, Bureau of Digital runs a series of “camps,” “summits,” and workshops for digital project managers, operations managers, creative directors, and — rather uniquely — the agency owner.
I jumped at the chance to attend, and I’m glad I did. In the 15 years Elexicon has been in business, I’ve never had this kind of opportunity to meet and share experiences with my peers. I have to admit, the idea of comparing notes with other owners was as intimidating as it was intriguing, but once I immersed myself with the group I felt right at home. When over a hundred passionate digital agency owners take time out of their busy and hectic schedules and get together to exchange stories, develop relationships, break bread and share ideas, lots of good things happen. Richard Banville of Fresh Tilled Soil shared his findings from research on (literally) how the very best agencies become the best. Tracey Halvorson of FastSpot gave a talk on client relationships. Karen Lyons of ClockWork presented on work/life balance and how for owners it’s not so much a balance as a blend — “it’s all life!” The inimitable Mike Monteiro gave us heartfelt advice on how NOT to screw up design presentations; and Bryan Zmijewski of ZURB, creators of the Foundation responsive framework talked about the opportunities and pitfalls of developing a “side” project or product.
What I learned
Agency ownership is an art. This was my biggest takeaway, the realization that the most successful interactive agency owners manage their business like one big digital project. They bring their same idealism for strategy and planning, ideation, people-centered design, sensible technology roadmaps, clear communication and project management to the art of running an enterprise.
Different paths, similar passion. Each owner at the summit “got here” differently. Andi Graham of Big Sea delivered a great talk on her “accidental agency,” while other visionaries had seemingly drawn up the blueprints for their agency in grade school. (Me? I fall somewhere in-between … Elexicon story fell into the right place/right time category.) Even though we all traveled different roads to get here, it seems we’re all now on a similar path and share a common passion.
This is a sincere and generous group that I hope to join up with again at a future summit. Insights and ideas flowed freely among the group, with the full intention of helping make each other and their businesses better. The focus was on strengthening the value of digital consultancy services — everything from strategy and design to development to marketing — to the benefit of not only these agencies and their teams but also to clients and their customers.
What I learned about Elexicon
We’re the same… I didn’t walk away from Summit with a new plan to turn Elexicon 180° upside down and try all the new ideas I learned from the industry’s leading agencies. That’s not why I attended, so thank goodness! On the contrary, the Summit validated many of our existing practices and processes while simply adding some helpful new perspectives. It was nice to see and share that we’re doing a lot of things right and that “it ain’t broke.” Many highly successful agencies of all shapes and sizes, literally from across the globe were represented, and Elexicon fit right in.
…But not totally the same. Elexicon is in its 15th year and this accomplishment really stood out in my conversations with other owners, where I received many congratulations on our longevity. Over those years I think we’ve created our own unique way of doing things in some facets of the agency business, that have led us to be very fortunate in the areas of client relationships and team culture. I returned to Grand Rapids feeling like I’d learned a lot but that perhaps a few of the newer agencies and younger owners I talked to at the summit may have learned a bit from me, too.
We’re onto something. While I first attended Owner Summit in 2015, I first heard of Bureau of Digital’s Owner Camps and Owner Summits about a year earlier. During that year of waiting for the next Summit to happen so I could attend, I drew inspiration from the “camp/summit” concept and started an “Agency Camp” within Elexicon during the summer of 2014. With an entire treasure trove of new ideas and insights from Owner Summit, we’re doing Agency Camp 2015 this summer.
The concept of Agency Camp is, in a nutshell, getting together as a team every so often in the morning and talk about how to make ourselves and our agency better. This will be a topic of a near-future blog post of its own, so stay tuned. In the meantime I’ll just close with a word of thanks to the Bureau of Digital crew for the Owner Summit opportunity and the way it inspired our Agency Camp, and I look forward to attending again!
MWUX 2014: A Recap
Posted by: Calvin Chopp
Part of our business model at Elexicon is continued education and training through conferences and other group learning experiences.
I recently I had the opportunity to attend the Midwest User Experience Conference (MWUX) in Indianapolis. MWUX is a smaller conference, but it packs some great sessions with engaging speakers on topics like design and development, as well as the future of this industry, and what we can expect to see and ultimately contribute if we apply ourselves.
I was able to pick up on a few key themes during the conference, each of which I think will be useful for my own workflow, as well as our agency in general.
Learn, teach, repeat.
Many of the speakers touched on the concepts of learning and teaching. There were talks on managing your UX team, learning how to learn again, how to work well with developers, and how to become more valuable by how we articulate our designs and process.
Jared Spool opened the conference Friday morning with a thought-provoking talk on the nature of today’s designers, the design and technology industry as a whole, and what needs to be done on the individual level to ensure that we as designers are able to keep up with the demand on our industry.
Jared asked questions like, “Why don’t design students come out of school knowing about responsive design or how to create mobile apps?” and “ Why are we having a tough time keeping up with the pace of innovation?” Jared focused on how it’s not enough to know what you were taught, but that we need to take our learning to the next level: where we know the right questions to ask as well as the right things to research to further develop our skillset and hone in our toolbox for designing the technology, applications and digital products we imagine.
Jared’s point was it’s not enough to know what we do and how we do it today. To be successful in this industry, we need to make a commitment to lifelong learning, as well as teaching. Jared explained that one of the most effective ways we learn is through teaching — taking a concept or practice that we know, and sharing it with fellow colleagues or people interested in the field. Being able to articulate why we do what we do not only helps us in our own process, but it also helps us to establish value for the work we do for our clients.
This need for passionate designers, especially user experience designers, Jared explained, is more necessary than ever before. In the U.S alone, there are over 24,000 unfilled user experience jobs. In reality, it’s a two-fold problem. There are just not enough qualified people to fill these positions. And employers don’t fully understand what they need to be looking for to actually fill these positions.
HR personnel for these companies call the user experience candidates they’re looking for “unicorns”, because of their rarity and scarcity. Large companies are buying up design agencies that understand and have expertise with user experience. These companies grasp the need for, and value of, a strong digital identity, and what that means for overall customer care. They see that there’s something missing in their digital offerings, and that they aren’t outfitted to appropriately meet that need, but that it’s important enough to take such drastic measures.
Whether individuals within these companies have the foresight to see the need, or consultants or agencies are pointing out the gap, it’s undeniable that there’s a growing disparity between the ever expanding digital landscape, and a full understanding of how we as designers best use and harness these concepts for our clients. It’s more important than ever for us as designers to be on top of our game.
The screen is [not] the limit
Related to the ever-expanding digital horizon, another topic that a number of speakers presented on was the changing landscape of the devices and screens we design for.
This obviously isn’t anything new, with the booming popularity of responsive design, native apps and a technological landscape that appears to have no bounds. Whether it’s the new 5K retina display on the new iMac, the tiny displays of smart watches or other wearables, or the forecasted landscape of no physical screens at all (it’s closer than you think), we as designers need to stop thinking so flat.
I’m not talking ‘flat design’ either, so you Apple/anti-skeuomorphic design toters can cool your washed out muted red blood. When I say “flat”, I’m referring to the linear content and content transitions we’re accustomed to. Beyond the fact that the technology we’re designing for, be it a browser or operating system, can handle so much more than the simple content transitions of the past, we also need to take into consideration how we can use these transitions and layering of content to create a more dynamic, user-focused experience.
We’re at a tipping point with how we interact with content and data, and it’s equally important that we find that balance between using these new new features to enrich the experience, and not letting that experience distract from the content, or become confusing for the user to navigate.
We don’t know what we don’t know.
Now we come full-circle.
We don’t know what we don’t know, and more importantly our clients don’t know what they don’t know.
It’s pretty typical that clients come to their agency with a project, usually accompanied with a project outline, some sort of project scope, and if, they’re ambitious, maybe even a projected project timeline. Depending on the client and their background, this may be perfectly acceptable.
But when was the last time you went to the doctor, and told him why your knee hurt, and how much time you had available for your full recovery? Not a perfect comparison, I know, but you get the idea.
It’s important that we as design professionals help knead and shape our clients in such a way that they understand this is our specialty, and we need to help set expectations on project scope, realistic timelines and what we can do within the time that we have available. Doing so will help to create happier clients, happier designers and happier developers on your team, and in the long run you’ll help to create a more valuable product. You’re also boosting your own credibility as an agency by offering solutions and producing results.
By articulating your work, designs, and process confidently and with excitement to your client, you’re getting them excited about the work being done. If you’re not buying what you do, neither is your client.
Because we’re experts at what we do, and have committed to lifelong learning because we love what we do (right?), chances are we have a leg up on our clients regarding something that they could be either doing differently, or aren’t doing [yet]. That’s the thing that would bring value to them and their customers if done right.
In the end, whether you call yourself a designer, a user experience professional, or whatever title seems fitting or trendy now, it’s your responsibility educate yourself, research what you do, as well as new and emerging services and technologies. You should be able to articulate what you do and present new services and products in a way to your clients that’s compelling and shows the value that would be added by incorporating them into their project.
The Liberation of Limitations
Posted by: Calvin Chopp
“When forced to work within a strict framework the imagination is taxed to its utmost – and will produce its richest ideas. Given total freedom the work is likely to sprawl.” — T.S Eliot
One of the things I enjoy most about being a designer is having clients who trust my ability to create something that represents them to their customers. It’s a big responsibility, and one that agencies shouldn’t take lightly. Part of this design process of getting a project off the ground is the initial phase of creating design options and different comps for the client’s consideration. In other words, choices.
Here’s the thing … growing up we’re basically taught that freedom is maximizing choices. The freedom of choice, right? You want running shoes? Here’s 50 different shoe companies offering 15 models in 5 different colors, each. The freedom to choose!
As a client, what could be greater than handing a project over to a competent designer, and giving them the freedom to “do your thing and make something great out of this”, letting them go to town creating the next big thing for you? The designer would have unlimited choices with branding profiles, the freedom to use their discretion regarding typography, mood boards and content transitions — everything up to their professional expertise, which you’re paying for. Sounds great, right?
Unfortunately, the very freedom that clients often give can become the very bondage that slows the creative process, and ultimately blows up budgets and timelines. Or, on the flip side, leaves the client with a final product that didn’t quite live up to expectations, assuming any expectations were set.
Bob Garfield talks about the ‘tyranny of freedom’ and the ad industry’s obsession with breaking rules in his book And Now a Few Words from Me. He uses the example of a child, and how “lack of boundaries does not liberate, it enslaves…”. His point is what looks on the surface to be confining can sometimes be liberating, and the lack of boundaries can promote indecision for the designer.
It’s the client’s responsibility to set these boundaries. It’s the designer’s responsibility to help walk the client through that process and answer questions that, at times, the client may not know to ask.
To think outside the box, there has to first be a box.
Deep right? Bear with me — I’ll try to not get too zen, but it’s valid. It’s important to understand that creativity thrives on constraints. If you have a wide open plain of choices, that creates a load of pressure, especially given that almost every project comes with a budget and a set timeline, both of which already affect the project scope. When designers are given context — restrictions and limitations — it stimulates creativity.
Here’s an example. I want you to sit at your desk, grab a blank sheet of paper, and I want you to draw something cool. Anything. Oh, and you only have 5 minutes. Feel free to email me your creations at calvin@elexicon.com. (No seriously, your submissions would make my day). Chances are if you took my example seriously, you’d sit there for half that time deliberating on what exactly to draw. The other half of the time would be spent quickly throwing together whatever it was that you settled on, and at the 5 minute mark, you’d likely not be incredibly happy with the results, or you’d second-guess your decision.
OK, now I want you to take the same 5 minute slot, and this time I’m going to give you a scene — a set of limitations. This time, its the zombie apocalypse and I want you to draw your war vehicle with all it’s weaponry that you’re going to drive to survive the hungry hordes. If you’re anything like me, your mind is immediately racing with all the guns and gadgets and armor that you’re going to attach to the outside of your car!
The example is silly, but this same concept rings true with project scopes and outlines that we designers receive from clients — the better we understand the project challenges and scope from the client, the higher the likelihood that we’re going to not only come in on budget and within the timeframe, but also that you’ll get more creative, better quality work.
Airbnb’s Elegant Makeover
Posted by: Brion EriksenI’m always attentive to advertising and marketing and brands, and our agency is especially attuned to revamps and refreshes, keeping tabs on blogs like Brand New. Airbnb recently updated their branding and, in my opinion, has really nailed it. The animation explaining the evolution and meaning of their clever new “Belo” logo sums up their re-focused mission nicely. It’s a delightful exploration: Just scroll down a bit on their home page.

As a past customer, they’ve really captured the essence of the value that I find in Airbnb: What they distill down to “Belonging.” I’ve rented spaces in San Francisco and New Orleans, staying in neighborhoods rather than hotel districts located near tourist attractions or convention centers. Both experiences gave me and my family the feeling of what it would be like to actually live in these historic and diverse cities, as opposed to a “just visiting” hotel stay. I’d call that belonging, alright.
This branding work reminds me of the popular TED Talk by Simon Sinek and his book, “Start With Why.” If you haven’t seen the talk, I’d recommend it … I’ve embedded it below. Once you’ve watched it, you’ll see how Airbnb has captured their “Why:” The central belief or ideal that drives a great business, inspires their employees and enchants their customers. Their “Why” statement would basically be their tagline: “Belong Anywhere.”

{kind=link}